Optimizing word embeddings for the web
miroojin / February 2019 (1378 Words, 8 Minutes)
Introduction
For a lot of NLP tasks, word embeddings have become an ubiquitous feature engineering technique for extracting meaning out of text data. Word embeddings (or word vectors) are used to efficiently represent unique words in a corpus as vectors. These dense vectors capture a word’s meaning, its semantic relationships and the different type of contexts it is used in.
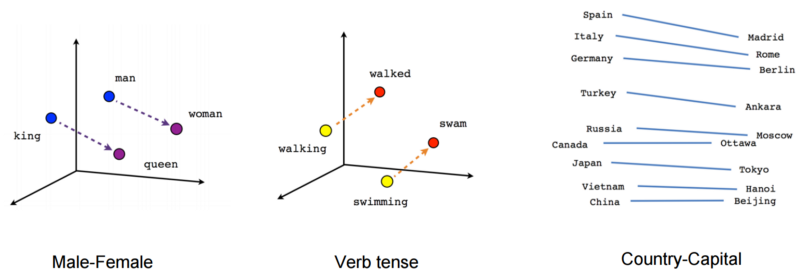 |
|---|
| Word vectors represented in 2D and 3D spaces. The semantic relationships between gender, verb tenses and countries and their capitals are clearly visible. |
Word embeddings are generated by training a large text corpus on predictive neural models (skip-gram, CBOW) or statistical models (GloVe). But instead of training from scratch, deep learning practitioners often use pre-trained word embeddings which are re-usable in various NLP tasks like sentiment analysis, language modeling and machine translation.
Optimizing for the web
Deep learning can be utilized in many ways to improve the user experience on web apps. While building such features, it makes a lot of sense to handle the model inference on the browser because of reasons like data privacy, accessibility, and low-latency interactiveness. One of the biggest hurdles with running deep learning models in the browser is that these models often require a large number of parameters which result in a large memory and storage footprint.
 |
|---|
| Gmail’s smart compose feature is a good example of using deep learning models for improving the user experience on web apps |
Although word embeddings are great, the pre-trained models are too large in size to be deployed to a browser or mobile device. To reduce the size of word vectors, researchers have developed various vector compression techniques. In this blog post, I will be exploring and applying a few of these techniques on FastText’s pre-trained word vectors. The resultant vectors are then bundled with a JS library which can be used in web apps.
Code & Demo
If you’d like to dive right into the code, you can go through this python script.
I’ve also created a demo where you can run nearest neighbor searches and word analogy tests: https://mb-14.github.io/embeddings.js/
Loading FastText vectors into Gensim
For this experiment, we’ll be using the 300 dimensional word vectors for 50k most common English words only. Instead of downloading FasText’s official vector files which contain 1 million words vectors, you can download the trimmed down version from this link.
Gensim’s word analogy test
Gensim provides a nifty utility function to measure how accurately the vectors have captured the semantic relationships between different word pairs. It does this by evaluating different word analogy questions. For instance, the solution to the analogy question: man is to woman what king is to ______? is queen and should be verified by our model using simple algebraic operations:
\[vec(king) - vec(man) + vec(woman) \approx vec(queen)\]Since the compression techniques are going to be lossy, we will be using the word analogies test in our experiments to measure the drop in accuracy after each compression step. For the analogy questions, we will be using a list provided by Google which tests different types of analogies like geographical facts, morphological relationships and gender based relationships.
Loading vectors into Gensim and evaluating accuracy:
from gensim.models import KeyedVectors
def compute_accuracy(model):
accuracy, _ = model.evaluate_word_analogies('questions-words.txt', restrict_vocab=50000)
print("Accuracy: {:f}%".format(accuracy*100))
model = KeyedVectors.load_word2vec_format('crawl-300d-50K.vec')
# Compute baseline accuracy
compute_accuracy(model)
Output:
Accuracy: 87.078803%
This the accuracy of the original FastText vectors which will be our baseline. Now lets start applying compression techniques to these vectors.
Compression technique 1: PCA dimensionality reduction
Principal Component Analysis (PCA) is a simple but popular technique for finding patterns in high dimensional data. PCA is used abundantly in all forms of data analysis - from neuroscience to computer graphics. The idea behind PCA is to perform linear transformations on a high dimensional dataset to construct a new set of features or Principal Components which summarize the dataset using a lesser number of dimensions. Using scikit-learn’s PCA module, we are going to reduce the dimensionality of our embeddings from 300D to 150D.
def reduce_dimensions_pca(vectors, dimensions=150):
reduced_vectors = PCA(n_components=dimensions).fit_transform(vectors)
return reduced_vectors
original_embeddings = model.embeddings
reduced_embeddings = reduce_dimensions_pca(original_embeddings)
# Create a new model with the reduced embeddings and calculate the accuracy
words = [model.index2word[idx] for idx in range(len(reduced_embeddings))]
model = KeyedVectors(vector_size=reduced_embeddings.shape[1])
model.add(words, reduced_embeddings, replace=True)
compute_accuracy(model)
Output:
Accuracy: 85.662505%
There is no considerable drop in accuracy! Let’s see if we can compress our embeddings even further.
Compression technique 2: Product quantization
Product quantization is a vector quantization technique which produces a more compact representation of data while maintaining a minimal loss in information. The basic idea behind product quantization is to split the vectors into sub-regions and approximate the representation of a sub-region with the closest matching centroid. Doing this allows us to store the vectors much more efficiently—instead of storing the original floating point values for each vector, we’re just going to store centroid IDs as integers. A vector can later be reconstructed by making lookups to the centroid database.
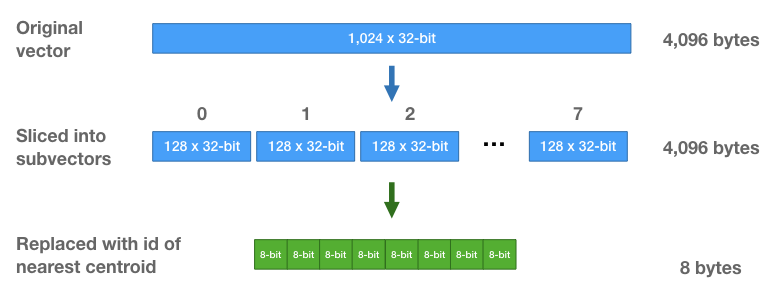 |
|---|
| Vector compression using product quantization. Image taken from Chris McCormick’ blog. |
To better understand how product quantization works, you should definitely read Chris McCormick’s tutorial about product quantizers: http://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/
We’re going to use python’s pqkmeans library to generate our database of centroids and assign centroid IDs for each word. Each word vector of 150D (after PCA) will be transformed to a compressed representation of 30 centroid IDs.
import pqkmeans
def product_quantize(vectors, subdims=30, centres=1000):
encoder = pqkmeans.encoder.PQEncoder(iteration=40, num_subdim=subdims, Ks=centres)
encoder.fit(vectors)
vectors_pq = encoder.transform(vectors)
reconstructed_vectors = encoder.inverse_transform(vectors_pq)
return reconstructed_vectors, vectors_pq, encoder.codewords
reconstructed_embeddings, codes, centroids = product_quantize(reduced_embeddings)
# Compute accuracy of new model
words = [model.index2word[idx] for idx in range(len(reconstructed_embeddings))]
model = KeyedVectors(vector_size=reconstructed_embeddings.shape[1])
model.add(words, reconstructed_embeddings, replace=True)
compute_accuracy(model)
Output:
Accuracy: 81.957310%
Lets do a size comparison between the original embeddings and the codes + centroids generated using product quantization
original_size = original_embeddings.nbytes
new_size = codes.nbytes + centroids.nbytes
print("Size reduction: {:f}%".format((original_size - new_size) * 100 / original_size))
Output:
Size reduction: 93.000000%
That’s a pretty significant reduction in size with only a small decrease in accuracy. Now that we’ve compressed our vectors to a reasonable size, we can deploy them to the browser!
Loading vectors using tensorflow.js
The final codes and centroids generated using product quantization along with the vocabulary are bundled into a JSON file. The vectors are then loaded on the browser using tensorflow.js. I’ve written a javascript library with tfjs which lets you unpack the vectors and reconstruct word embeddings by making lookups to the database of centroids. It also lets you search a word’s nearest neighbors and evaluate word analogies.
You can checkout the implementation on Github: https://github.com/mb-14/embeddings.js
Future explorations
The word analogy test might not be a good way to measure the usefulness of word embeddings in practical NLP tasks. Instead, we can perform benchmarking on a task like sentiment analysis for a better measure of accuracy.
Deploying word embeddings is only the first step to implementing natural language based deep learning models in the browser. Fortunately, libraries like tensorflow.js make it very easy to run complex graphs on the browser.