Building markov chains in golang
miroojin / October 2018 (2218 Words, 13 Minutes)
Introduction
A while back, I was looking into a language modeling problem and I came across a simple but powerful tool called Markov chains.
A Markov chain is a mathematical system which keeps track of transitions between different states and tells you the probability of a transition occurring between two states. The states can be anything like words, numbers, weather conditions, stock market trends etc.
Markov chains have been around for a while now. They are widely applied in finance, game theory, ecology and meteorology. These are fields where you often need to model real-world systems in which transitions between different events are not deterministic but occur with a certain probability. The predictive typing feature on your mobile keyboards is implemented using Markov chains. Even Google’s PageRank algorithm, which powers their search, is a type of Markov chain! Markov chains also have a fun application of generating random text sequences like Trump tweets, Garfield comics, and even entire subreddits!
Since there was no proper implementation of markov chains in golang, I decided to build a library myself.
 |
|---|
| Garfield comic generated using markov chains |
How do markov chains work?
A Markov chain is a stochastic process which follows the Markov property. The Markov property states that for a process, the probability of a transition to a future state depends only on the current state and not on the sequence of states that preceded it. Mathematically this can be written as:
\[\boldsymbol{P(S_{i+1} | S_{i}, S_{i-1}, S_{i-2}, \ldots, S_2, S_1) = P(S_{i+1} | S_{i})}\]Explanation: The probabilty of the occurrence of future state \(S_{i+1}\) given the occurrance of a sequence of states: \(S_{1}, S_{2}, S_{3}, \ldots, S_{i-1}, S_{i}\) is equal to the probability of \(S_i+1's\) occurrence given the occurrence of the current state \(S_{i}\).
This simple assumption makes it easy to calculate the conditional probability of a state transition. The markov property can be assumed to be true for most (although not all) real world cases.
To build a markov chain out of a sequence, all we need to do is store the transition probabilities between consecutive states. The transition probability from state \(S_i\) to state \(S_j\) is calculated by dividing the count of all transitions from \(S_i\) to \(S_j\) by the total count of transitions out of \(S_i\).
Consider the following sequence of words:
I am Sam. I am an engineer. I like coding.
A markov chain with transition probabilities for these words would look like:
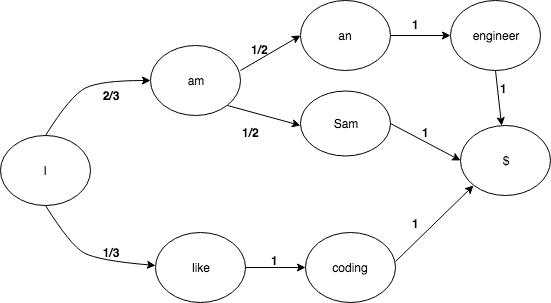 |
|---|
| The $ token represents the end of a sentence state. |
This chain can also be represented in a state transition matrix:
| I | am | an | coding | Sam | engineer | like | $ | |
|---|---|---|---|---|---|---|---|---|
| I | 0 | 2/3 | 0 | 0 | 0 | 0 | 1/3 | 0 |
| am | 0 | 0 | 1/2 | 0 | 1/2 | 0 | 0 | 0 |
| an | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| coding | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Sam | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| engineer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| like | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| $ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
With this matrix, we can easily lookup the transition probability between different states. For example, the transition probability from the word “am” to “an” would be stored in \(transition\_matrix[\boldsymbol{am}][\boldsymbol{an}]\)
Higher order markov chains and n-gram modelling
The Markov property is only valid for a first order markov chain. We can also create higher order markov chains where the future state outcome probabilty is dependent on more than one preceding states. This lets the chain remember more history of past state transitions. An n-th order markov chain satisfies the following condition:
\[\boldsymbol{P(S_{i+1} | S_{i}, S_{i-1}, S_{i-2}, \ldots, S_2, S_1) = P(S_{i+1} | S_{i}, S_{i-1}, S_{i-n})}\]Explanation: In this case, the condition probability of a future outcome is dependent on the past n states.
You can use a higher order markov chain to build an n-gram model. An n-gram model is a statistical language model with applications in speech recognition and machine translation. An n-gram is a collection of n items. An item can be a letters, words, phonemes, syllables or even DNA base pairs based on the application.
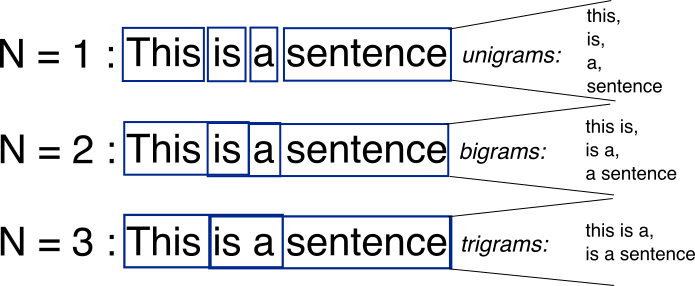 |
|---|
| Different types of n-grams extracted from a sentence |
In the example above (I am Sam. I am an engineer. I like coding.), we had split the sequence of items into bigrams and calculated their transition probabilities.
Bigrams: I am, am Sam, I am, am an, an engineer, I like, like coding
Instead of using bigrams, we could split the sequence into trigrams and build a 2nd order markov chain.
Trigrams: I am Sam, I am an, am an engineer, I like coding
In a 2nd order Markov chain, the probabilty of a future transition depends on the previous two words. In this case our transition probabilty matrix would look like:
| I | am | an | coding | Sam | engineer | like | $ | |
|---|---|---|---|---|---|---|---|---|
| I am | 0 | 0 | 1/2 | 0 | 1/2 | 0 | 0 | 0 |
| am Sam | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| I like | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| like coding | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| am an | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| an engineer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| coding $ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Sam $ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| engineer $ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Building a markov chain in golang
To implement a markov chain in golang, all we need to do is implement a data structure to hold the transition probability matrix. The easiest way would be to use a two dimensional float64 array. But, as our state dictionary size increases, the transition matrix tends to become sparser and our 2D array will end up with a large number of zeroes. Instead, I’ve used a nested map which is better suited to hold a sparse matrix.
Lets start by defining types:
// sparseArray holds all the transition counts for a given state.
type sparseArray map[string]int
type Chain struct {
//freqMat holds the transition counts for all our states
frequencyMat map[string]sparseArray
Order int //Order represents the order of our markov chain
}
func NewChain(order int) *Chain {
return &Chain{Order: order, frequencyMat: make(map[string]spareArray)}
}
Now we need to create functions to add sequences to our markov chain and calculate the transition probability between two states:
//Add adds the transition counts to the chain for a given sequence of words
// Implementation of the array(), concat(), and MakePairs() helper functions
// can be found in https://github.com/mb-14/gomarkov/blob/master/helpers.go
func (chain *Chain) Add(sequence []string) {
// Pad the sequence with start and end tokens
// array(token, n) returns a array of length n filled with the token
startTokens := array("^", chain.Order)
endTokens := array("$", chain.Order)
tokens := concat(startTokens, sequence, endTokens)
// Extract n-grams from the sequence based on the chain order
// and return state pairs
pairs := MakePairs(tokens, chain.Order)
// Iterate throught the state pairs and add their transition counts
for i := 0; i < len(pairs); i++ {
pair := pairs[i]
if chain.frequencyMat[pair.CurrentState.Key()] == nil {
chain.frequencyMat[pair.CurrentState.Key()] = make(sparseArray, 0)
}
// Increment the transition count for a state pair
chain.frequencyMat[pair.CurrentState.Key()][pair.NextState]++
}
}
//TransitionProbability returns the transition probability between two states
func (chain *Chain) TransitionProbability(next string, current []string) (float64, error) {
if len(current) != chain.Order {
return 0, errors.New("N-gram length does not match chain order")
}
// Calcuate the total transition counts from the current state by
// summing up the individual transition counts
arr := chain.frequencyMat[current.key()]
sum := float64(arr.sum())
// Fetch the transition count of current --> next from the frequency matrix
freq := float64(arr[nextState])
return freq / sum, nil
}
Lets test our implementation now.
chain := NewChain(1)
chain.Add([]string{"I", "am", "Sam"})
chain.Add([]string{"I", "am", "an", "engineer"})
chain.Add([]string{"I", "like", "coding"})
prob, _ := chain.TransitionProbability("am", []string{"I"})
fmt.Println(prob)
//Output: 0.6666666666666666
Final result: gormakov
You can check out the complete implementation here: https://github.com/mb-14/gomarkov
I’ve added optimizations like string pooling and ensured thread safety so that sequences can be added to a chain from multiple goroutines. The project also has some interesting examples like:
-
Gibberish username detection: Builds a character level 2-gram model out of a list geniune usernames. The character transition probabilities in such a model will be high for genuine user names and low for gibberish character sequences like: dgwdtbghtwh
> ./gibberish -train > ./gibberish -u jack.reacher Score: 0.184727 | Gibberish: false > ./gibberish -u fgsdgtqh Score: -0.739162 | Gibberish: true -
Faker HN post generator: This example builds a markov chain from the top 500 HN post titles generates fake HN post titles. This example also trains the markov chain using concurrent goroutines
#Train on HN top stories > ./fakernews -train > ./fakernews Output: Show HN: What Wal-Mart Knows About Customers' Habits (2004) > ./fakernews Output: A modern computer model could rival the Large Hadron Collider
Future explorations
Markov chains have definitely increased my interest in language modelling and their applications in various NLP tasks. Although such statistical models are interesting, they have their shortcomings when dealing with large datasets. In such cases, neural language models like LSTM networks perform better in terms of generalization and scalability. I plan to explore these methods and improve my understanding of sequence modelling with RNNs. I might even write a blog post about my findings. Until then, feel free to generate some really hilarious HN posts.